# 输出输入 - IO包
# IO包介绍
在 Go 中,输入和输出操作是使用原语实现的,这些原语将数据模拟成可读的或可写的字节流。
为此,Go 的 io 包提供了 io.Reader 和 io.Writer 接口,分别用于数据的输入和输出,如图:

Go 官方提供了一些 API,支持对内存结构,文件,网络连接等资源进行操作
本文重点介绍如何实现标准库中 io.Reader 和 io.Writer 两个接口,来完成流式传输数据。
# 基础的 - Reader以及Writer
# Reader 接⼝
io.Reader 表示一个读取器,它将数据从某个资源读取到传输缓冲区。在缓冲区中,数据可以被流式传输和使用。
如图:

对于要用作读取器的类型,它必须实现 io.Reader 接口的唯一一个方法 Read(p []byte)。
换句话说,只要实现了 Read(p []byte) ,那它就是一个读取器。
# Reader 接⼝的定义
type Readre interface {
Read(p []byte) (n int, err error)
}
官⽅⽂档中关于该接⼝⽅法的说明:
- Read 将 len(p) 个字节读取到 p 中。它返回读取的字节数 n(0 <= n <= len(p)) 以及任何遇到的错误。即使 Read 返回的 n < len(p),它也会在调⽤过程中使⽤ p 的全部作为暂存空间。若⼀些数据可⽤但不到 len(p) 个字节,Read会照例返回可⽤的数据,⽽不是等待更多数据。
- 当 Read 在成功读取 n > 0 个字节后遇到⼀个错误或 EOF (end-of-file),它就会返回读取的字节数。它会从相同的调⽤中返回(⾮nil的)错误或从随后的调⽤中返回错误(同时 n == 0)。
- ⼀般情况的⼀个例⼦就是 Reader 在输⼊流结束时会返回⼀个⾮零的字节数,同时返回的 err 不是 EOF 就是 nil。⽆论如何,下⼀个 Read 都应当返回 0,EOF。
- 调⽤者应当总在考虑到错误 err 前处理 n > 0 的字节。这样做可以在读取⼀些字节,以及允许的 EOF ⾏为后正确地处理 I/O 错误
- 也就是说,当 Read ⽅法返回错误时,不代表没有读取到任何数据。调⽤者应该处理返回的任何数据,之后才处理可能的错误。
# Reader 接⼝ - 实例
package main
import (
"fmt"
"io"
"os"
"strings"
)
type Readre interface {
Read(p []byte) (n int, err error)
}
func main() {
reader := strings.NewReader("HEELO GO 20210531")
p := make([]byte, 5) // 决定了每一次取出的值类型以及数量
for {
n, err := reader.Read(p)
if err != nil {
if err == io.EOF {
fmt.Println("EOF:", n)
break
}
fmt.Println("err:", err)
os.Exit(1)
}
fmt.Println(n, string(p[:n]))
}
}
// 结果:
5 HEELO
5 GO 2
5 02105
2 31
EOF: 0
# 其他调用方式
将 io.Reader 作为参数,也就是说,可以从任意的地方读取数据,只要来源实现了 io.Reader 接口。比如,我们可以从标准输入、文件、字符串等读取数据
// 从标准输⼊读取
data, err = ReadFrom(os.Stdin, 11)
// 从普通⽂件读取,其中 file 是 os.File 的实例
data, err = ReadFrom(file, 9)
// 从字符串读取
data, err = ReadFrom(strings.NewReader("from string"), 12)
# 网上的几个实例
过滤掉非字母字符
type alphaReader struct {
// 资源
src string
// 当前读取到的位置
cur int
}
// 创建一个实例
func newAlphaReader(src string) *alphaReader {
return &alphaReader{src: src}
}
// 过滤函数
func alpha(r byte) byte {
if (r >= 'A' && r <= 'Z') || (r >= 'a' && r <= 'z') {
return r
}
return 0
}
// Read 方法
func (a *alphaReader) Read(p []byte) (int, error) {
// 当前位置 >= 字符串长度 说明已经读取到结尾 返回 EOF
if a.cur >= len(a.src) {
return 0, io.EOF
}
// x 是剩余未读取的长度
x := len(a.src) - a.cur
n, bound := 0, 0
if x >= len(p) {
// 剩余长度超过缓冲区大小,说明本次可完全填满缓冲区
bound = len(p)
} else if x < len(p) {
// 剩余长度小于缓冲区大小,使用剩余长度输出,缓冲区不补满
bound = x
}
buf := make([]byte, bound)
for n < bound {
// 每次读取一个字节,执行过滤函数
if char := alpha(a.src[a.cur]); char != 0 {
buf[n] = char
}
n++
a.cur++
}
// 将处理后得到的 buf 内容复制到 p 中
copy(p, buf)
return n, nil
}
func main() {
reader := newAlphaReader("Hello! It's 9am, where is the sun?")
p := make([]byte, 4)
for {
n, err := reader.Read(p)
if err == io.EOF {
break
}
fmt.Print(string(p[:n]))
}
fmt.Println()
}
//结果:
HelloItsamwhereisthesun
多重Reader,更新 alphaReader 以接受 io.Reader 作为其来源
type alphaReader struct {
// alphaReader 里组合了标准库的 io.Reader
reader io.Reader
}
func newAlphaReader(reader io.Reader) *alphaReader {
return &alphaReader{reader: reader}
}
func alpha(r byte) byte {
if (r >= 'A' && r <= 'Z') || (r >= 'a' && r <= 'z') {
return r
}
return 0
}
func (a *alphaReader) Read(p []byte) (int, error) {
// 这行代码调用的就是 io.Reader
n, err := a.reader.Read(p)
if err != nil {
return n, err
}
buf := make([]byte, n)
for i := 0; i < n; i++ {
if char := alpha(p[i]); char != 0 {
buf[i] = char
}
}
copy(p, buf)
return n, nil
}
func main() {
// 使用实现了标准库 io.Reader 接口的 strings.Reader 作为实现
reader := newAlphaReader(strings.NewReader("Hello! It's 9am, where is the sun?"))
p := make([]byte, 4)
for {
n, err := reader.Read(p)
if err == io.EOF {
break
}
fmt.Print(string(p[:n]))
}
fmt.Println()
}
alphaReader 如何与 os.File 结合以过滤掉文件中的非字母字符
func main() {
// file 也实现了 io.Reader
file, err := os.Open("./alpha_reader3.go")
if err != nil {
fmt.Println(err)
os.Exit(1)
}
defer file.Close()
// 任何实现了 io.Reader 的类型都可以传入 newAlphaReader
// 至于具体如何读取文件,那是标准库已经实现了的,我们不用再做一遍,达到了重用的目的
reader := newAlphaReader(file)
p := make([]byte, 4)
for {
n, err := reader.Read(p)
if err == io.EOF {
break
}
fmt.Print(string(p[:n]))
}
fmt.Println()
}
# 总结
io.EOF 变量的定义:var EOF = errors.New("EOF"),是 error 类型。根据 reader 接口的说明,在 n > 0 且数据被读完了的情况下,返回的 error 有可能是 EOF 也有可能是 nil
# Writer 接口
io.Writer 表示一个编写器,它从缓冲区读取数据,并将数据写入目标资源。
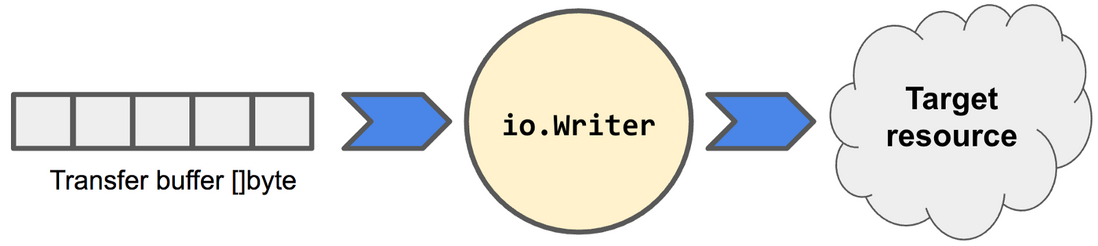
对于要用作编写器的类型,必须实现 io.Writer 接口的唯一一个方法 Write(p []byte)
同样,只要实现了 Write(p []byte) ,那它就是一个编写器。
# Writer 接⼝的定义
type Writer interface {
Write(p []byte) (n int, err error)
}
官方文档中关于该接口方法的说明:
- Write 将 len(p) 个字节从 p 中写入到基本数据流中。
- 它返回从 p 中被写入的字节数 n(0 <= n <= len(p))以及任何遇到的引起写入提前停止的错误。
- 若 Write 返回的 n < len(p),它就必须返回一个 非nil 的错误。
# Writer 接⼝的实例
package main
import (
"bytes"
"fmt"
"os"
)
type Writer interface {
Write(p []byte) (n int, err error)
}
func main() {
proverbs := []string{
"Channels orchestrate mutexes serialize",
"Cgo is not Go",
"Errors are values",
"Don't panic",
}
var writer bytes.Buffer
for _, p := range proverbs {
n, err := writer.Write([]byte(p))
if err != nil {
fmt.Println(err)
os.Exit(1)
}
if n != len(p) {
fmt.Println("failed to write data")
os.Exit(1)
}
}
fmt.Println(writer.String())
}
结果:
Channels orchestrate mutexes serializeCgo is not GoErrors are valuesDon't panic
# 网上的几个实例
字节序列写入 channel
type chanWriter struct {
// ch 实际上就是目标资源
ch chan byte
}
func newChanWriter() *chanWriter {
return &chanWriter{make(chan byte, 1024)}
}
func (w *chanWriter) Chan() <-chan byte {
return w.ch
}
func (w *chanWriter) Write(p []byte) (int, error) {
n := 0
// 遍历输入数据,按字节写入目标资源
for _, b := range p {
w.ch <- b
n++
}
return n, nil
}
func (w *chanWriter) Close() error {
close(w.ch)
return nil
}
func main() {
writer := newChanWriter()
go func() {
defer writer.Close()
writer.Write([]byte("Stream "))
writer.Write([]byte("me!"))
}()
for c := range writer.Chan() {
fmt.Printf("%c", c)
}
fmt.Println()
}
要使用这个 Writer,只需在函数 main() 中调用 writer.Write()(在单独的goroutine中)。
因为 chanWriter 还实现了接口 io.Closer ,所以调用方法 writer.Close() 来正确地关闭channel,以避免发生泄漏和死锁
# ReaderAt 和 WriterAt 接口
# ReaderAt 接口
type ReaderAt interface {
ReadAt(p []byte, off int64) (n int, err error)
}
官方文档中关于该接口方法的说明:
ReadAt 从基本输入源的偏移量 off 处开始,将 len(p) 个字节读取到 p 中。它返回读取的字节数 n(0 <= n <= len(p))以及任何遇到的错误。
当 ReadAt 返回的 n < len(p) 时,它就会返回一个 非nil 的错误来解释 为什么没有返回更多的字节。在这一点上,ReadAt 比 Read 更严格。
即使 ReadAt 返回的 n < len(p),它也会在调用过程中使用 p 的全部作为暂存空间。若可读取的数据不到 len(p) 字节,ReadAt 就会阻塞,直到所有数据都可用或一个错误发生。 在这一点上 ReadAt 不同于 Read。
若 n = len(p) 个字节从输入源的结尾处由 ReadAt 返回,Read可能返回 err == EOF 或者 err == nil
若 ReadAt 携带一个偏移量从输入源读取,ReadAt 应当既不影响偏移量也不被它所影响。
可对相同的输入源并行执行 ReadAt 调用。
可见,ReaderAt 接口使得可以从指定偏移量处开始读取数据。
# 实例
package main
import (
"fmt"
"strings"
)
type ReaderAt interface {
ReadAt(p []byte, off int64) (n int, err error)
}
func main() {
reader := strings.NewReader("Go您好")
p := make([]byte, 6) // 定义取出数据的类型以及数量
n, err := reader.ReadAt(p, 2) // 2为偏移量
if err != nil {
panic(err)
}
fmt.Printf("%s, %d\n", p, n)
}
// 结果:
您好, 6
# WriterAt 接口
type WriterAt interface {
WriteAt(p []byte, off int64) (n int, err error)
}
官方文档中关于该接口方法的说明:
WriteAt 从 p 中将 len(p) 个字节写入到偏移量 off 处的基本数据流中。它返回从 p 中被写入的字节数 n(0 <= n <= len(p))以及任何遇到的引起写入提前停止的错误。若 WriteAt 返回的 n < len(p),它就必须返回一个 非nil 的错误。
若 WriteAt 携带一个偏移量写入到目标中,WriteAt 应当既不影响偏移量也不被它所影响。
若被写区域没有重叠,可对相同的目标并行执行 WriteAt 调用。
我们可以通过该接口将数据写入到数据流的特定偏移量之后。
# 实例
package main
import (
"fmt"
"os"
)
type WriterAt interface {
WriteAt(p []byte, off int64) (n int, err error)
}
func main() {
file, err := os.Create("ss.txt") // 打开文件
if err != nil {
panic(err)
}
defer file.Close() // 函数结束后关闭文件
file.WriteString("您好GO") // 写入文件
n, err := file.WriteAt([]byte("您好"), 8) // 在文件中偏移8字节数据写入您好二个字,成功返回写入数量的字节
if err != nil {
panic(err)
}
fmt.Println(n)
}
//结果:
6
# 分隔线
基于io.Reader 和 io.Writer 接口封装的接口还有很多。。。。。。
# ReadAll函数 一次性读取 io.Reader 中的数据
很多时候,我们需要一次性读取 io.Reader 中的数据,通过上一节的讲解,我们知道有很多种实现方式。考虑到读取所有数据的需求比较多,Go 提供了 ReadAll 这个函数,用来从io.Reader 中一次读取所有数据。
func ReadAll(r io.Reader) ([]byte, error)
阅读该函数的源码发现,它是通过 bytes.Buffer 中的 ReadFrom (opens new window) 来实现读取所有数据的。该函数成功调用后会返回 err == nil 而不是 err == EOF。(成功读取完毕应该为 err == io.EOF,这里返回 nil 由于该函数成功期望 err == io.EOF,符合无错误不处理的理念)
# ReadDir函数-输出目录下的所有文件以及子目录
在 Go 中如何输出目录下的所有文件呢?首先,我们会想到查 os 包,看 File 类型是否提供了相关方法(关于 os 包,后面会讲解)。
其实在 ioutil 中提供了一个方便的函数:ReadDir,它读取目录并返回排好序的文件和子目录名( []os.FileInfo )。通过这个方法,我们可以很容易的实现“面试题”。
func main() {
dir := os.Args[1]
listAll(dir,0)
}
func listAll(path string, curHier int){
fileInfos, err := ioutil.ReadDir(path)
if err != nil{fmt.Println(err); return}
for _, info := range fileInfos{
if info.IsDir(){
for tmpHier := curHier; tmpHier > 0; tmpHier--{
fmt.Printf("|\t")
}
fmt.Println(info.Name(),"\\")
listAll(path + "/" + info.Name(),curHier + 1)
}else{
for tmpHier := curHier; tmpHier > 0; tmpHier--{
fmt.Printf("|\t")
}
fmt.Println(info.Name())
}
}
}
# ReadFile 和 WriteFile 函数- 读或写(全部)
ReadFile 读取整个文件的内容,在上一节我们自己实现了一个函数读取文件整个内容,由于这种需求很常见,因此 Go 提供了 ReadFile 函数,方便使用。ReadFile 的实现和ReadAll 类似,不过,ReadFile 会先判断文件的大小,给 bytes.Buffer 一个预定义容量,避免额外分配内存。
ReadFile 函数的签名如下:
func ReadFile(filename string) ([]byte, error)
函数文档:
ReadFile 从 filename 指定的文件中读取数据并返回文件的内容。成功的调用返回的err 为 nil 而非 EOF。因为本函数定义为读取整个文件,它不会将读取返回的 EOF 视为应报告的错误。(同 ReadAll )
WriteFile 函数的签名如下:
func WriteFile(filename string, data []byte, perm os.FileMode) error
函数文档:
WriteFile 将data写入filename文件中,当文件不存在时会根据perm指定的权限进行创建一个,文件存在时会先清空文件内容。对于 perm 参数,我们一般可以指定为:0666,具体含义 os 包中讲解。
ReadFile 源码中先获取了文件的大小,当大小 < 1e9 时,才会用到文件的大小。按源码中注释的说法是 FileInfo 不会很精确地得到文件大小。